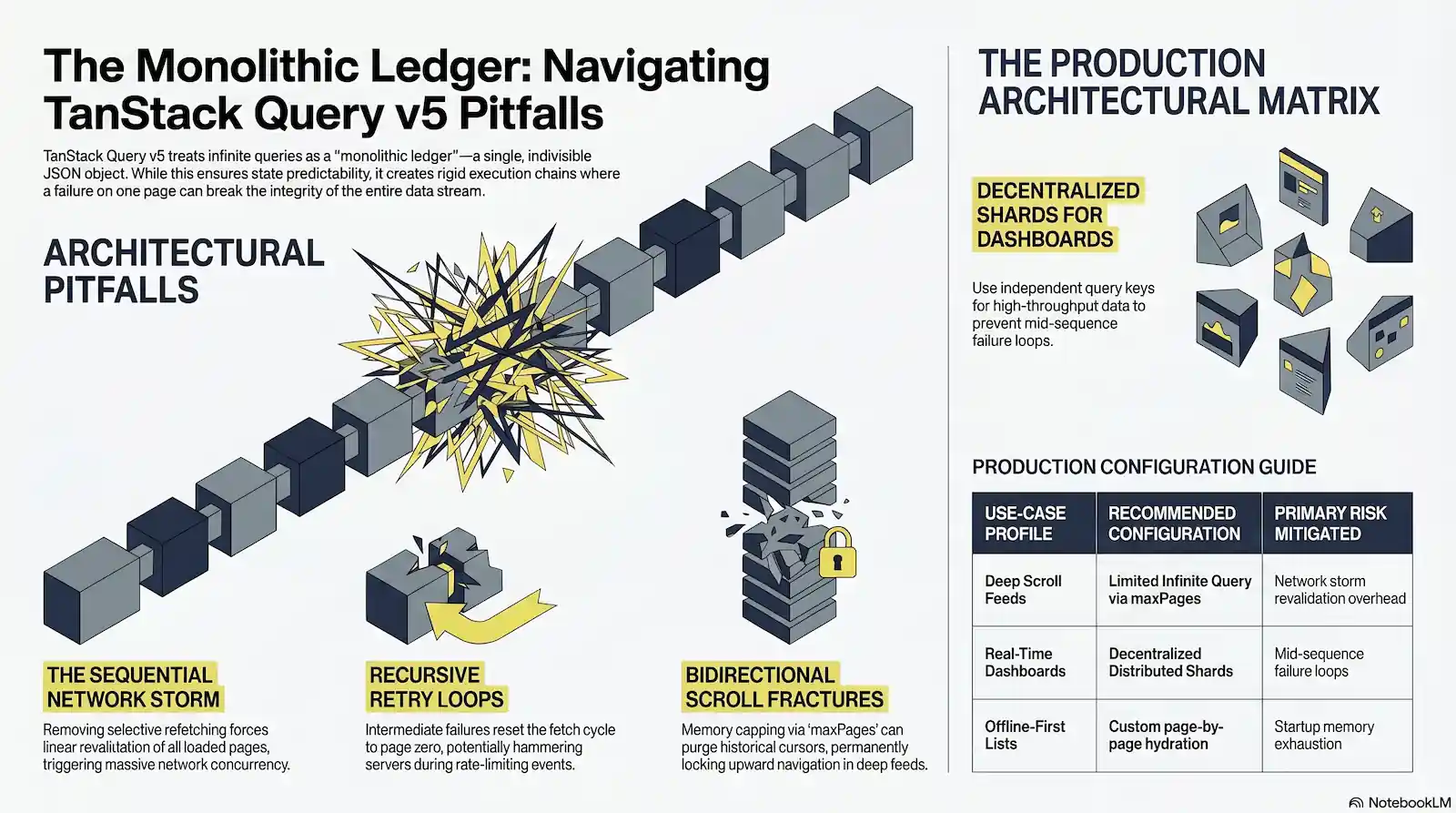
Engineering teams frequently adopt client-side abstraction layers under the assumption that pagination utilities handle continuous data feeds with isolated, out-of-the-box optimization. The operational reality of the version 5 execution engine challenges this expectation, revealing a distinct gap between localized data needs and the framework’s core architectural layout. The library forces an explicit paradigm shift toward state predictability and typed configuration. Under the hood, the engine treats paginated datasets not as independent distributed shards, but as an unyielding, unified ledger. Treating paginated data as a sequential monolithic ledger creates rigid execution chains, where a fracture on a single page breaks the integrity of the whole system.
This monolithic design pattern introduces structural complexities into real-world applications. The architecture of TanStack Query v5 represents a major shift toward state predictability and typed configuration. However, the deprecation of key APIs and the introduction of memory-limiting features have created complex integration challenges for high-throughput, paginated, and offline-first web applications.
By binding paginated data into a single cache entry stored as a unified JSON object containing a pages array and a matching pageParams array, v5 builds a highly rigid dependency graph. The core engine manages the entire pagination history as an indivisible state container rather than independent queries occupying distinct cache keys. While this ledger paradigm ensures that synchronization remains predictable, it prevents the management of single pages in isolation. Systems architects must assess whether their platforms can support an execution model where individual page lifecycle states remain tied to the continuous record of the complete cache entry.
The Monolithic Refetch Engine & Network Storm Mechanics
TanStack Query v5 enforces an explicit architectural shift by removing selective page refetching capabilities entirely. Framework maintainers frame this as a correction of an architectural flaw : “As for v5 there is no more way to refetch last page of infinite query… In v4, we used invalidateQueries and, with refetchPage, we compared the index of the page returned with the index of the page we wanted to fetch and only returned true if it matched… Infinite Queries aren’t designed to view a single page in isolation. It’s one cache entry that is chunked up into multiple fetches. That’s why the refetchPage api was a mistake.”
By discarding the refetchPage API, the execution engine treats paginated datasets not as independent distributed shards, but as an indivisible, unified ledger. An infinite query occupies a single, monolithic cache entry structured as a unified JSON object. This object encapsulates a pages array and a corresponding pageParams array, which the core engine models as a strict linked list. The operational validity of page N relies directly on the cursors established by page N-1. Treating paginated data as a sequential monolithic ledger creates rigid execution chains, where a fracture on a single page breaks the integrity of the whole system.
Marking a cache entry as stale forces a strict sequential loop. The client cannot query an isolated middle page. Instead, the engine initiates processing at the initialPageParam and iterates lineally through all loaded page parameters.
This strict sequential loop was intentionally chosen by framework maintainers to prevent UI bugs. If a server-side record deletion shifts items across page boundaries, refetching an isolated page would cause elements to slide into neighboring arrays, producing visible duplicate items in the client UI.
When combining this sequential architecture with standard component lifecycle defaults, client-side performance breaks down. The default configuration of refetchOnMount: true dictates that when a user returns to a deeply scrolled feed, the component mount event marks the entire monolithic cache as stale. The engine immediately executes a background synchronization storm. If a user has loaded 20 pages of data, the client issues 20 consecutive HTTP requests to revalidate the cache sequentially. This introduces massive network concurrency overhead. The engine processes these HTTP requests back-to-back because the subsequent fetch parameter remains completely unknown until the preceding network promise fully resolves.
The Rate-Limiting Trap & Retry Loop Vulnerabilities
Intermediate page synchronization failures during background cache revalidation expose a fundamental structural flaw in the TanStack Query v5 architecture. When a platform interacts with cursor-based microservices enforcing token-bucket or strict Transactions Per Minute (TPM) rate limits, the library’s monolithic model becomes an operational liability. Treating paginated data as a sequential monolithic ledger creates rigid execution chains, where a fracture on a single page breaks the integrity of the whole system. If an application has populated multiple pages in the cache, any subsequent manual or automated refetch must evaluate the entire history in a strict sequence.
The core failure mechanics reveal an architectural mismatch during this revalidation path. As documented in Issue #8046: “When fetching next pages with fetchNextPage and the queryFn rejects with an error response, the request is retried as expected using the same page params. However, I noticed retried requests from a manual or automated refetch will start over back to the first page after the first error response is encountered… I expect a failed page request to retry using the same page params and continue onto the next page request once the retry succeeds.”
Consider a user session with five pages of hydrated ledger data. If the background refetch routine successfully syncs page 0, page 1, and page 2, but encounters an HTTP 429 Too Many Requests or a network timeout on page 3, the engine initiates its configured exponential backoff retry mechanism. Instead of executing the retry against the failed cursor of page 3, the engine aborts the active sequence entirely.
The monolithic sequential refetch engine contains a critical vulnerability during background or manual refetches. If an intermediate page request fails due to an upstream rate limit or transport timeout, the query core abandons the active pagination sequence, ignores the current cursor, and forcibly resets the cycle back to initialPageParam. This causes an automated retry loop that hammers the initial endpoints recursively.
This destructive fallback behavior transforms transient network friction into permanent client-side state failures. Because the engine handles retry executions by starting over from page 0, the client recursively requests the initial datasets while the upstream rate limit remains active. The system remains trapped in an infinite loop, continually consuming client-side data quotas, exhausting backend resources, and locking the UI in a perpetual loading state.
MaxPages Side Effects & Bidirectional Scroll Fractures
Memory capping via the maxPages configuration introduces structural compromises that threaten the consistency of continuous feeds. Platforms implement this property to mitigate DOM bloat and constrain client memory consumption during deep scroll operations. However, the engine achieves this limitation by mutating the cache layout. Treating paginated data as a sequential monolithic ledger creates rigid execution chains, where a fracture on a single page breaks the integrity of the whole system. When an application fetches data beyond the defined threshold, the query engine forces an array truncation loop.
The core engine executes eviction through explicit array shifts:
// Core implementation of the maxPages eviction loop during forward pagination
if (maxPages && pages.length > maxPages) {
pages.shift(); // Removes the first page from memory
pageParams.shift(); // Removes the first page parameter from memory
}This shifting mechanism creates a volatile sliding window that destabilizes cursor-based APIs. By executing pages.shift() and pageParams.shift(), the engine destroys the foundation of the ledger, clearing initial cursors and structural offsets from memory. For token- or cursor-based backend architectures, backward navigation relies completely on lookups within this historical pageParams array.
When a user attempts to reverse direction and scroll upward, the engine executes getPreviousPageParam. Because the array truncation has purged the earliest keys, the historical cursor parameters no longer exist in the cache.
When maxPages enforces structural pruning on cursor-dependent APIs, it strips away the historical query parameters required to re-traverse the pagination pipeline backward. This causes getPreviousPageParam to evaluate as undefined, freezing upward boundaries and leaving the client unable to fetch historical segments.
The query engine enters an unrecoverable upward scroll lock. The system treats the missing cursor state as the absolute boundary of the dataset. This architectural fracture traps the interface in a dead state, preventing the recovery of purged pages and forcing a complete refetch of the ledger to restore bidirectional navigation.
Persistence Engine Hydration Bypass and Memory Bloat
A direct contradiction exists between the memory-saving objectives of the maxPages configuration and the brute-force execution path of the framework’s hydration pipeline. While runtime configurations attempt to bound the active cache footprint, offline persistence mechanisms operate under a completely separate execution model. Treating paginated data as a sequential monolithic ledger creates rigid execution chains, where a fracture on a single page breaks the integrity of the whole system. When integrating persistence utilities, this monolithic structure causes severe resource contention during startup.
The underlying integration conflict stems from how state restoration is handled. As documented in framework discussions: “The experimental_createQueryPersister stores and restores the entire InfiniteData object… as a single cache entry. When an infinite query is first used: persisterFn checks query. state. data === undefined. Retrieves ALL pages from storage… This causes performance issues when many pages are cached, as all pages are loaded into memory and rendered at once.”
Offline persistence tools, including the experimental_createQueryPersister and synchronous storage plugins, treat the serialized InfiniteData structure as an atomic, unified cache block. During application initialization, the persister bypasses the engine’s lazy-loading, on-demand layout mechanics. It refuses to incrementally stream pages or respect the memory-eviction bounds configured for live user sessions. Instead, the initialization sequence instantly hydrates the entire multi-page historical payload into memory simultaneously.
The framework’s persistence architecture completely undermines the runtime safeguards provided by memory-limiting parameters. Because the persistence layer operates at the cache-entry level rather than the individual page-element level, it re-injects historical data payloads into the active state indiscriminately on boot, leaving systems vulnerable to startup memory exhaustion.
This indiscriminate loading produces immediate structural failure points at the UI layer. Restoring an expansive, un-pruned ledger block on application boot forces massive DOM inflation and heavy layout shifts as the rendering engine processes every historical page concurrently. For users on low-end hardware or mobile devices, this instantaneous memory inflation degrades runtime performance, locking the main thread and inducing severe input latency before the application achieves interactivity.
Soft Persistence Failures & Synchronous Cache Desync
Assuming that manual cache writes through setQueryData act as a deterministic single source of truth is a dangerous architectural miscalculation. Developers routinely manipulate cache states directly to achieve instantaneous UI updates during mutations. However, in an infinite query context, this execution path introduces silent state fractures. Treating paginated data as a sequential monolithic ledger creates rigid execution chains, where a fracture on a single page breaks the integrity of the whole system. When an application overrides specific segments of this ledger manually, it alters the internal control flags governing cache synchronization.
The vulnerability stems from the internal side effects of direct cache modification. When setQueryData is called, the library internally sets the query state as valid and updates its timestamp. However, if this manual write lacks the required meta parameters or occurs exactly as a separate component mounts with refetchOnWindowFocus enabled, the internal isInvalidated flag resets to false while underlying pages remain functionally desynchronized from the actual server state.
Calling setQueryData on an infinite query does not just append raw items; it fundamentally rewrites the core execution metadata. By resetting the query’s isInvalidated flag to false, the cache engine assumes the client state matches the server perfectly. This silences the background synchronization routines necessary to correct structural shifts in paginated endpoints.
This mechanics-level override triggers severe race conditions during high-concurrency operations. If a user refocusses the browser window or triggers a component remount precisely as the manual write resolves, the query engine evaluates the newly minted isInvalidated: false state. The framework treats the modified local cache entry as completely fresh, skipping the automated recovery syncs that would otherwise reconcile the data. Consequently, the client-side pages diverge entirely from the remote database state. This creates a state of soft persistence failure where the UI displays stale, mutated, or missing items while the framework’s internal flags report perfect structural integrity.
The Final Verdict: Production Architectural Matrix
Treat infinite query configuration as an explicit performance contract, not an unconfigured runtime convenience. Systems architects must align framework mechanics with backend architectural boundaries to avoid catastrophic cache failures and network thrashing. Treating paginated data as a sequential monolithic ledger creates rigid execution chains, where a fracture on a single page breaks the integrity of the whole system. The selection of an engine configuration mode dictates a platform’s operational resilience against memory degradation, silent offline state rollback, and recursive rate-limiting loops. Choosing between this integrated ledger layout and a decentralized distributed shard model determines how downstream microservices handle concurrent client-side mutations.
The following architectural matrix maps specific use-case profiles to their optimal query core configuration modes:
| Use-Case Profile | Recommended Configuration | Primary Risk Mitigated | Memory Impact |
| Deep Infinite Scroll Feeds (>10 Pages) | Limited Infinite Query via maxPages configuration with absolute payload cursors. | Client-side network storm revalidation overhead and unexpected API data quota exhaustion. | Strictly bounded by page size threshold limits. |
| High-Throughput Real-Time Dashboards | Decentralized Distributed Shards via useQueries leveraging independent, granular pagination keys. | Mid-sequence failure loops, rate-limiting traps, and initial page parameter resets. | Isolated and managed per distinct query observer instance. |
| Offline-First Paginated Lists | Custom page-by-page persister hydration paired with strict explicit state validation. | Indiscriminate full-cache block hydration memory bloat and immediate application boot thread lockup. | Lazily expanded in memory as individual data segments are accessed. |
Enforcing clear runtime constraints over internal cache behavior preserves system integrity. The TanStack Query v5 engine demands absolute synchronization between server-side pagination layouts and client-side resource controls to guarantee predictable execution profiles and system stability.
For a visual breakdown of handling caching states, direct cache manipulation, and standard invalidation mechanics within this framework version, see this guide on Mastering TanStack Query v5 Infinite Loading and Cache Mechanics. This video provides context on updating the internal cache object structure and managing data keys in real-world applications.
FAQs
refetchPage API was completely removed in v5. Infinite queries are now treated as single, monolithic cache entries. To simulate selective refetching, you must use a custom wrapper hook that dynamically slices the in-memory cache data before calling refetch, or switch to an array of independent useQueries instances. refetchOnMount enabled, the synchronization engine loops through every page parameter currently saved in history to avoid duplicate items or data gaps, creating a high-overhead network storm on deeply scrolled feeds. maxPages evicts the initial pages from memory to save on footprint, it shifts and drops the corresponding keys from the internal pageParams array. If your API relies on looking up historical array positions to page backward, getPreviousPageParam will receive a truncated history, return undefined, and lock scrolling. setQueryData after calling invalidateQueries, the framework interprets the manual mutation as fresh, accurate server data. It resets the internal isInvalidated flag back to false. If your application is configured with staleTime: Infinity, the background validation is cancelled, leaving the UI showing the local optimistic state indefinitely.